Data scuffing, on the other hand, http://paxtonddem058.bearsfanteamshop.com/30-huge-data-statistics-2023-amount-of-information-created-on-the-planet refers to the extraction of data from any resource. Generally, regardless of the approaches involved, we describe the retrieval of data from the site as scraping. Not only do they check out pages, but they additionally collect all the pertinent details and index it at the same time. There are a number of methods to obtain details and data from the Web. The two most preferred ways are Information Crawling and Information Scraping as called. Both web creeping and data scuffing are techniques of recovering data and the details required and procedures associated with getting them.
Internet scrapes extract certain data collections and can be "anything." It is likewise unneeded for an internet scraper to adhere to all the web links related to a web site. Web scuffing and API are 2 standard techniques used to draw out data. While both make the extraction procedure simpler and automated, each approach functions differently. Creeping is systematic link collection, while scratching is specific data extraction.
Generative AI: Privacy and tech perspectives - International Association of Privacy Professionals
Generative AI: Privacy and tech perspectives.
Posted: Tue, 28 Mar 2023 07:00:00 GMT [source]
Modern crawling bots are created to better understand what the limits of operations are and follow within the restrictions to avoid lawful complexities. Because of these technical advancements, the risk of upseting are very little. Internet scuffing is everything about the information - the information areas you intend to remove from details web sites. With scuffing you usually understand the target internet sites, you might not recognize the specific page URLs, but you know the domain names at least.
What Is Information Crawling?
Internet spiders are automated software programs that surf the internet and methodically accumulate information from websites. The procedure usually entails adhering to links from one web page to one more, and indexing the web content of each web page for later use. Crawling includes accumulating information from numerous websites or web pages. While information scratching is concentrated on particular elements on a single web page.
AI chatbots compared: Bard vs. Bing vs. ChatGPT - The Verge
AI chatbots compared: Bard vs. Bing vs. ChatGPT.
Posted: Fri, 24 Mar 2023 07:00:00 GMT [source]
It usually entails composing code to engage with a web site's HTML and draw out the wanted info. For instance, if you wished to remove a checklist of product names and prices from an e-commerce site, you could compose an internet scraper to do so. Our group of devoted and dedicated professionals is an one-of-a-kind combination of method, imagination, and modern technology. Both scratching and crawling are information removal methods that have been around for a very long time. Relying on your business or the sort of The original source solution you're seeking to get, you can go with either of both. It's important to understand that while they may show up the exact same on the surface, the steps involved are pretty various.
Obtain Data For Your Business
When they find web sites which contain information appropriate to a particular topic, the crawler will certainly make a note of that site and offer it a position in a customer's search engine result appropriately. Second, you may fall short to collect target data because some internet sites could have information clogs. This implies information from internet sites comes to be hardly available to crawlers. If youuse scrapes, you could be able to bypass this limitation. A scrape can give you accessibility to big proxy networks that can enable you Custom Business Intelligence Services to collect web data making use of numerous IPs.
- You aren't necessarily finding brand-new web content by doing a crawl on your own computer.
- The objective of creeping is commonly to produce an index or catalog of information, which can then be searched or assessed.
- Information scratching, on the other hand, refers to the extraction of data from any kind of source.
- Then for each and every new product, a scraper is made use of to draw out the new item's data, like the rate, images, item code, or description.
Information scratching has actually ended up being the best tool for company development over the last years. According to Mckinsey Global Institute, data-driven companies are 23 times more likely to obtain clients. They are also six times more likely to preserve customers and 19 times more likely to be rewarding. Leveraging this information allows business to make more informed choices and improve consumer experience.

On the other hand, information spiders are utilized in online search engine to supply the needed search results page. The high quality of the information obtained with internet scraping and internet crawling likewise varies. Internet scraping is frequently made use of to remove extremely targeted and exact data from websites, as the information is specifically targeted and the code used to extract it is generally more complex. Web crawling, on the other hand, can commonly be performed with easier code as it does not call for the very same degree of specificity in data extraction.
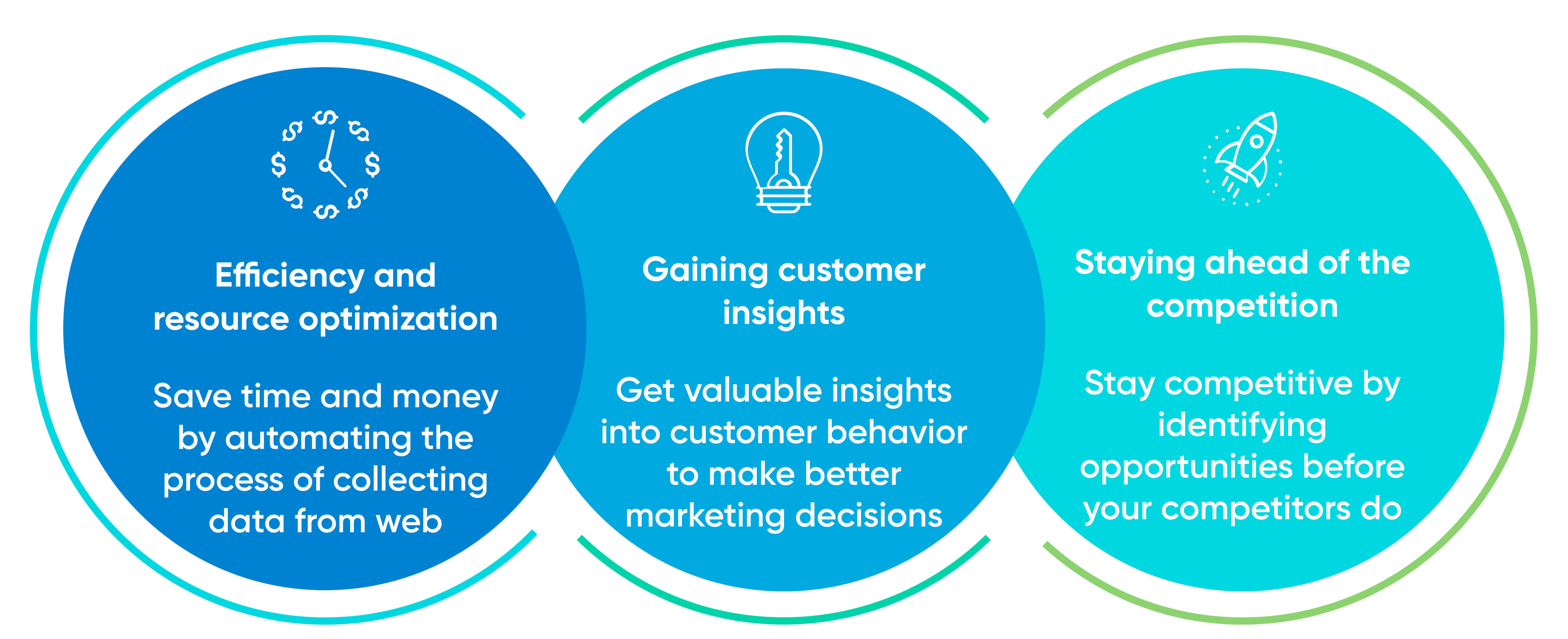
A lot of the usage cases for internet scuffing are in a business context. A company could intend to check what items its competitors are marketing and the prices they are offering them at. They might likewise intend to check web sites for any type of mentions of them or to discover data that will certainly help with their SEO strategy.